六、网络挖掘应用程序
1、B2C电子商务个性化体验——Amazon.com
网络挖掘的使用:
1)使用cookies识别用户;
2)对用户过去行为分析并同类型用户分组,以提供个性化消息、类别推荐、金盒子(gold box);
3)使用聚类、关联分析、时间序列分析等。
2、Web搜索——Google
网络挖掘的使用:
1)内容分析确定相关页面;
2)超链接分析根据质量对相关页面排名;
3、网络用户跟踪——Double Click
网络挖掘的使用:
1)使用特殊的cookie跟踪用户在多个站点之间的访问;
2)分析多站点行为;
3)使用DART系统提供广告服务。
4、了解用户社区——AOL
1)挖掘用户组的兴趣和观点;
2)针对特定群组推广新产品或发表关于某个问题的观点。
5、了解拍卖行为——eBay
eBay有详细的数据:拍卖历史记录、参与率、竞价数据、使用数据。
网络挖掘的使用:对参与者类型分类、对拍卖类型分类、确定欺诈性报价、确实拍卖成交。
6、个性化门户网站——MyYahoo
使用网络挖掘:
1)创建个性化消息;
2)基于偏好或位置推荐产品或保养;
3)根据偏好或使用发送媒体内容。
7、在线文档统计——CiteSeer
8、i-Mode –NTT D0C0Mo’s mobile internet accesssystem
有4000万用户从他们的手机访问互联网。
用户可以收发邮件、在线购物或理财、获取交通新闻和天气预报、搜索当地餐馆及其他东西。
9、v-TAG网络挖掘服务器
七、相关概念
1、兴趣度(Interestingness Measure[PT1998,C2000])
万维网上有两种资源:
网络结构(Web Structure)——反映作者关于浏览行为的观点;
网络使用(Web Usage)——反映用户的浏览行文。
所有与这些信息源矛盾的证据都将被称作“令人感兴趣的(interesting)”。
2、用户行为档案(User Behavior Profiles[MSSZ2002])
目标:理解复杂的人类决策过程。
方法:记录点击流数据;收集其他用户信息,比如人口统计数据和心理调查数据等。
级别:在一个网站内部,如Amazon.com;在整个万维网上,如Alexa研究和DoubleClick。
3、分布式网络挖掘(Distributed Web Mining)
动机:网络上的数据是巨大的,并且分布在不同的站点。
传统方法:把所有的数据整合到一个站点,然后进行必要的分析。
问题:耗时、不可伸缩。
解决方案:在不同的位置进行本地数据分析,建立整体模型。
应用程序:根据用户的“网络生活”(用户的兴趣、位置和行为)提供个性化的站点。
两种方法:隐式(Surreptious),不需要用户提交任何信息而跟踪用户在不同网站的访问行为;协作(Co-operative),用户行为报告给一个中央组织或数据库。
4、网络可视化(Web Visualization)
动机:网络数据挖掘提供了大量的信息,这些信息通过可视化工具可以更好地被理解,相比纯文本的表示方式。
著名开发工具(Prominent toolsdeveloped):WebViz、WUM(Web Utlization Miner)、WEEV、WebQuilt、Naviz。
5、主题提取(Topic Distillation)
定义:识别与查询主题相关的一组文档或其中的一部分。
方法:Kleinberg的Hubs and Authority;The FOCUSproject;Web Page Reputations;主题敏感的PageRank。
6、在线文档计量学(Online Bibiliometrics)
动机:在线文章比离线文章更多地被引用;更容易地互动和交流信息。
例子:SCI,ACM portal,CiteSeer,DBLP等。
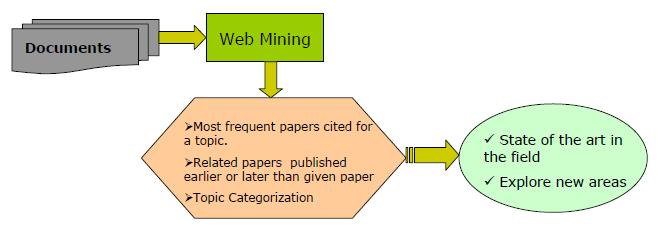
7、网页分类(WebPage Categorization)
定义:网页分类决定了一个网页所属的类别,这些类别是预先定义好的。
8、语义网络挖掘(Semantic Web Mining)
动机:从无结构的网络中自动检索文档是困难的;搜索引擎检索的文档在语义方面是不精确的。
语义网的最初想法:生成附加语义的文档;开发从结构化数据中根据语义挖掘信息的技术。
语义网格式:RDF,节点与附属的属性/值对可以模型化为一个有向的标签图;XML主题网可以由基础数据的语义形成,它可以被看作在线版本的打印索引和目录。
任务:应用网络挖掘技术理解网络上大量非结构化文档的本体;为现有的和未来的文档定义本体以使搜索更加精确。